Извлекаем аудио дорожку из видео файла с помощью ffmpeg в Linux
Jazz
Как извлечь аудио дорожку из видео файла в Linux..? Многие пользователи компьютера не раз сталкивались с такой задачей. В этом выпуске блога я покажу пример решения этой задачи на базе операционной системы с Linux. Решать эту задачу я буду в Debian, но все показанные здесь действия и команды актуальны для любой операционной системы, любого вендора Linux — Arch, Debian, Fedora, Gentoo, Ubuntu — показанные примеры можно реализовать на любой из перечисленных систем, если в системе установлен ffmpeg — продвинутый и всемогущий аудио/видео конвертер.
О задаче
Как известно, современные видео форматы являются контейнерами, объединяющими в один файл несколько параллельных потоков. Как правило, эти потоки имеют разную природу — аудио, видео, субтитры — но внутри контейнера синхронизированы между собой по времени воспроизведения. В некоторых ситуациях бывает необходимо извлечь из такого контейнера какой-то определённый поток и сохранить его в отдельном файле. Вот именно эту задачу я и буду решать в этой демонстрации.
Что значит извлечь? Компьютерный файл, это не картонная коробка, мы не можем его вскрыть лезвием ножа и просто достать желанную вещицу... Компьютерный файл имеет строго сконструированную по определённым правилам структуру данных, в которой каждому потоку определено своё место. Но при этом, с помощью специальных программных средств, любой из этих потоков можно воспроизвести отдельно, а значит, и скопировать в отдельный файл.
В этой демонстрации я буду иметь дело с самым обыкновенным видео файлом в формате MKV, в составе которого имеется, в том числе, две аудио дорожки. Я буду извлекать оригинальную англоязычную...
Извлекать аудио поток из видео файла можно в трёх различных вариантах:
-
копируя исходный поток в том виде, в котором он хранится в видео контейнере;
-
декодируя исходный поток в формат PCM Wav;
-
кодируя исходный поток в другой формат, любой другой, энкодером которого вы располагаете.
Далее я покажу все три варианта решения задачи и достижения поставленной цели с минимальными затратами.
Пара слов о ffmpeg
ffmpeg является специальным программным средством, с помощью которого можно воспроизвести каждый поток контейнера отдельно. Это утилита командной строки. У всех современных вендоров Linux эта программа имеется в их официальных хранилищах пакетов. В Debian и deb-совместимых операционных системах эту программу можно установить с помощью пакетного менеджера apt.
$ sudo apt install -y ffmpeg
В сути своей ffmpeg является коллекцией декодеров и энкодеров различных аудио и видео форматов. Понятно, что декодер преобразует тот или иной аудио поток в поток формата PCM Wav с заданными параметрами. А энкодер, в свою очередь, преобразует аудио поток формата PCM Wav в заданный формат. Извлекая аудио дорожку из видео файла с помощью ffmpeg и с преобразованием, можно использовать либо встроенный энкодер, либо сторонний энкодер.
На сегодняшний день наиболее часто в видео файлах встречаются аудио дорожки следующих форматов: dts, ac3, aac, mp3, vorbis, opus. Со всеми этими форматами ffmpeg умеет работать.
Определяем состав исходного контейнера
В моём распоряжении есть видео файл формата MKV с именем kino.mkv, с этим файлом я и покажу некоторые из множества возможных примеры манипуляций. Для начала необходимо определиться с составом исходного видео файла, сколько и каких именно потоков в этот файл упаковано.
В одном пакете с ffmpeg предоставляется программа ffprobe, она показывает всю доступную информацию о файле, состав контейнера, присоединённые к контейнеру метаданные, технические характеристики потоков. Поскольку меня интересует только состав контейнера, весь выхлоп ffprobe я буду отдавать по программному каналу на вход программе grep и уже с её помощью фильтровать данные по самому элементарному регулярному выражению — Stream — вот такой простой командой.
$ ffprobe kino.mkv 2>&1 >/dev/null | grep Stream
В этой команде конструкция 2>&1 >/dev/null указывает, что в программный канал отдаётся стандартный поток ошибок ffprobe, вместо её стандартного потока вывода. Внимание на следующий снимок экрана.
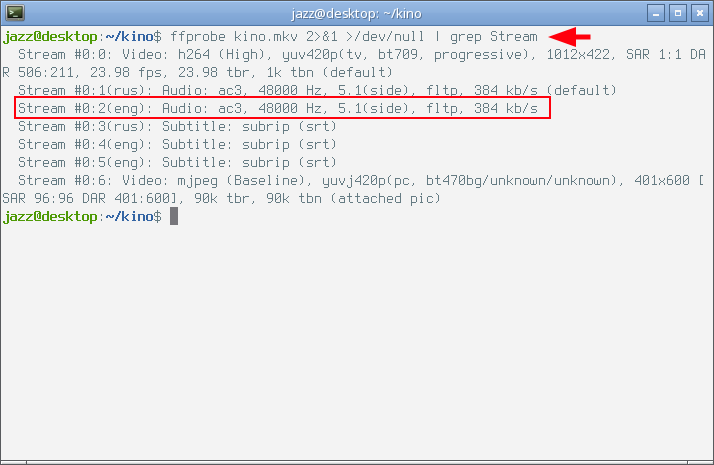
Как видно на снимке моего терминала с выхлопом предложенной команды, контейнер kino.mkv содержит в себе шесть потоков. Каждый поток имеет номер: #0:0, #0:1 и так далее. Аудио потоки хранятся в контейнере под номером #0:1 — русскоязычная дорожка, и под номером #0:2 — оригинальная англоязычная аудио дорожка. Оба потока имеют один формат и абсолютно идентичные технические параметры. Меня интересует оригинальная англоязычная дорожка — поток с номером #0:2. Определились, номер потока запомнили...
Копируем аудио поток в исходном состоянии
Определившись с номером интересующего меня исходного потока и его техническими параметрами, я могу достаточно просто скопировать этот поток в отдельный файл и впоследствии использовать этот файл в своих коварных, меркантильных целях. ffmpeg позволяет реализовать это действие следующей простой командой.
$ ffmpeg -i kino.mkv -v quiet -stats -vn -map 0:2 -codec:a copy -map_metadata -1 eng.ac3
Здесь следует обратить внимание на параметры команды, представленные её ключами:
-
-iзадаёт имя исходного файла; -
-v quietопределяет, что ffmpeg не будет печатать свой отчёт на терминал; -
-statsопределяет, что на терминал будет выводиться элементарна строка прогресса со статистикой кодирования; -
-map 0:2указывает номер исходного потока, этот номер я уже определил из выхлопа ffprobe; -
-vnуказывает программе, что видео поток кодировать не нужно; -
-codec:aуказывает на используемый при кодировании встроенный в ffmpeg энкодер или декодер, в данном случае я использовалcopy— исходный поток будет скопирован без преобразования; -
-map_metadata -1указывает, что метаданные транслировать не нужно; -
eng.ac3определяет имя полученного в результате исполнения этой команды файла.
Вбиваю команду в приглашение командной строки и жму enter, внимание на следующий снимок экрана.
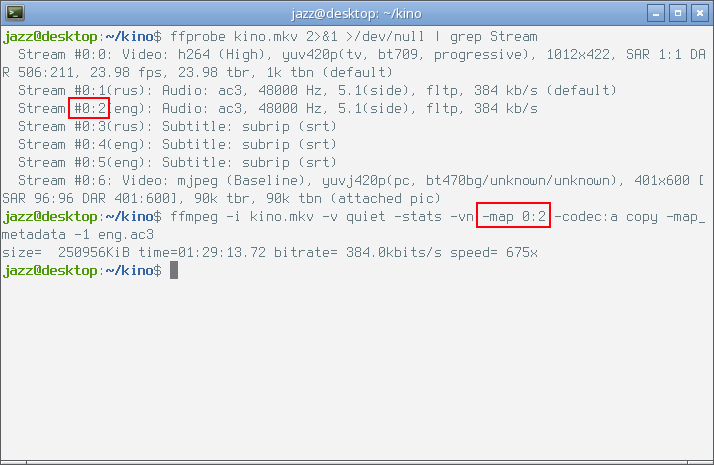
Как видно на снимке экрана выше, копирование аудио дорожки в исходном состоянии происходит на скорости 675x, в строке прогресса ffmpeg указаны также размер полученного файла в КиБ, длительность воспроизведения аудио дорожки и битрейт.
Давайте посмотрим, что расскажет программа ffprobe о полученном в результате такого кодирования файле.
$ ffprobe eng.ac3 2>&1 >/dev/null | grep Stream
В этой команде я заменил только имя файла. Внимание на следующий снимок экрана.
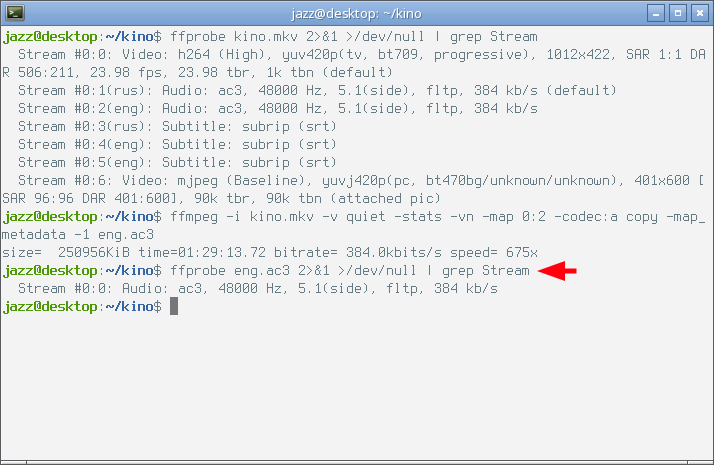
Видно, что хранящийся в полученном файле аудио поток абсолютно идентичен исходному аудио потоку, который хранится в контейнере kino.mkv. Цель достигнута, и теперь я могу делать с полученным файлом всё, что пожелаю.
Декодируем исходный аудио поток в PCM Wav
Если посмотреть на технические параметры исходного аудио потока, который хранится в видео контейнере, мы увидим его формат и количество каналов. В показанном примере аудио поток имеет шесть каналов, это обстоятельство влияет на размер полученного файла, чем больше каналов, тем больше данных необходимо хранить, тем больше дискового пространства будет занимать полученный файл. Чаще всего, извлечённый аудио поток хочется слушать на каком-либо мобильном устройстве, которое поддерживает ограниченное число форматов, как правило это MP3, AAC или WMA, реже Vorbis или Opus. Любой из этих перечисленных форматов можно получить из PCM Wav, и это значит, что извлекая аудио дорожку из видео контейнера её следует декодировать. В этом случае необходимость многоканального аудио отпадает, и вместе с декодированием следует ещё и преобразовать аудио поток в самое обычное стерео — два канала. Эту операцию достаточно легко реализовать следующей командой.
$ ffmpeg -i kino.mkv -v quiet -stats -vn -map 0:2 -codec:a pcm_s16le -ac 2 -map_metadata -1 eng.wav
В этой команде следует обратить внимание на ключ -codec:a, в этом ключе я использовал формат pcm_s16le. Ключ -ac 2 в этой команде определяет преобразование многоканального звукового потока в обычное стерео. Внимание на следующий снимок экрана.
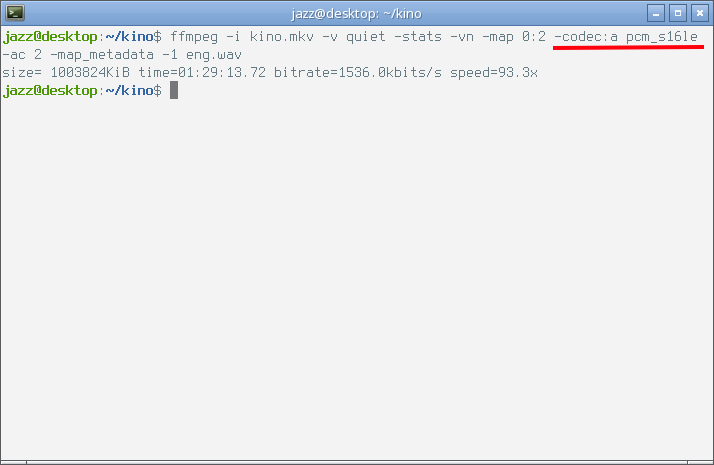
Как видно из строки прогресса исполненной команды на показанном снимке экрана, декодирование происходит намного медленнее копирования, а полученный файл при прочих равных имеет намного больший размер. Если посмотреть на полученный файл с помощью ffprobe, мы увидим следующие параметры потока.
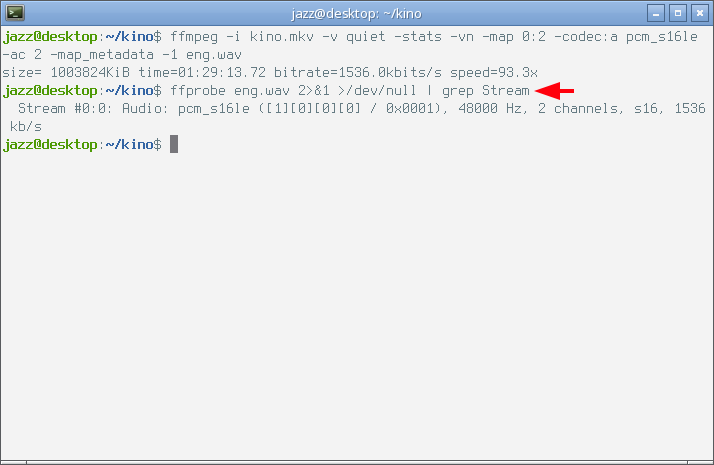
Полученный PCM Wav файл хранит никак не сжатый поток 16-битных чисел по одному на каждый канал с частотой дискретизации 48kHz — 48000 пар 16-битных чисел для каждой секунды звучания. Хранение такого объёма данных требует достаточно много дискового пространства, и для мобильных устройств использование этого формата конечно же будет нерациональным. Но PCM Wav без труда можно преобразовать в любой мобильный аудио формат. Сейчас я покажу, как...
Используем внешний энкодер
Допустим, что необходимо исходную аудио дорожку преобразовать в формат Opus. Нативный энкодер Opus в deb-совместимых операционных системах устанавливается вместе с пакетом opus-tools, установить его можно с помощью apt.
$ sudo apt install opus-tools
Программа энкодер Opus обычно имеет имя opusenc. И чтобы преобразовать исходный аудио поток в выбранный формат, я должен декодировать его с помощью ffmpeg в PCM Wav поток и отдать этот поток по программному каналу на вход энкодеру opusenc. Следующая "сложная" команда реализует это действие.
$ ffmpeg -i kino.mkv -v quiet -stats -vn -map 0:2 -codec:a pcm_s16le -ac 2 -map_metadata -1 -f wav - | opusenc - eng.opus --quiet
Здесь я декодирую с помощью ffmpeg исходную аудио дорожку в PCM Wav, но не сохраняю его в файл, а отдаю в программный канал в формате wav ключом -f wav, за которым следует дефис и вертикальная черта. После вертикальной черты следует внешний энкодер opusenc, которому я указал вместо имени входящего файла дефис — стандартный поток ввода. Далее следует имя получаемого файла и ключ --quiet, предотвращающий выхлоп opusenc. Внимание на следующий снимок экрана.
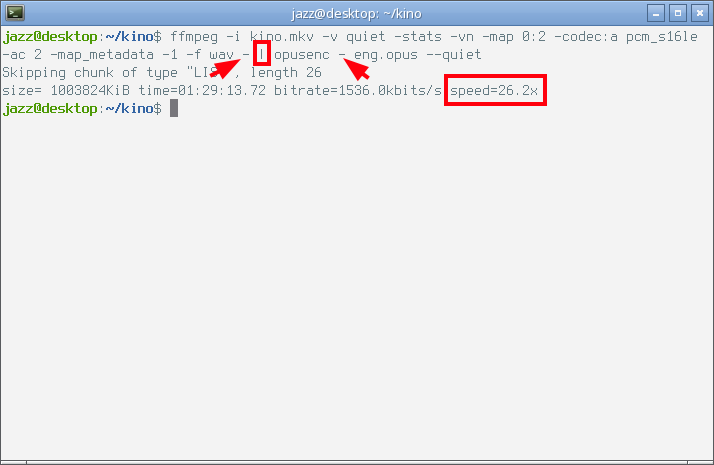
Как видно, кодирование внешним энкодером осуществляется с ещё меньшей скоростью, чем декодирование. Исполняемый процесс займёт некоторое время. При этом в строке прогресса ffmpeg показаны данные относящиеся только к процессу декодирования. Определить размер и параметры полученного файла можно с помощью ffprobe, либо любой другой аналогичной программы, например, opusinfo, в данном конкретном случае выхлоп будет выглядеть следующим образом.
$ opusinfo eng.opus
Processing file "eng.opus"...
New logical stream (#1, serial: 1c85a43a): type opus
Encoded with libopus 1.5.2, libopusenc 0.2.1
User comments section follows...
ENCODER=opusenc from opus-tools 0.2
Opus stream 1:
Pre-skip: 312
Playback gain: 0 dB
Channels: 2
Original sample rate: 48000 Hz
Packet duration: 20.0ms (max), 20.0ms (avg), 20.0ms (min)
Page duration: 1000.0ms (max), 1000.0ms (avg), 740.0ms (min)
Total data length: 57000055 bytes (overhead: 0.771%)
Playback length: 89m:13.728s
Average bitrate: 85.17 kbit/s, w/o overhead: 84.52 kbit/s
Logical stream 1 ended
Встроенный энкодер ffmpeg vs. сторонний энкодер
Как было отмечено выше, при преобразовании исходного аудио потока можно использовать либо встроенный в ffmpeg энкодер, либо любой внешний энкодер необходимого формата. Давайте рассмотрим вероятную разницу на примере энкодера AAC — яблочный формат.
AAC — это достаточно продвинутый, современный формат хранения сжатых аудио данных, в отличие от, скажем, очень распространённого, но слишком архаичного MP3. В коллекции ffmpeg есть встроенный энкодер этого формата, и воспользоваться им достаточно просто. Следующая команда позволит достигнуть поставленную цель.
$ ffmpeg -i kino.mkv -v quiet -stats -vn -map 0:2 -codec:a aac -b:a 160k -ac 2 -map_metadata -1 eng.m4a
В этой команде следует обратить внимание на ключ -codec:a, в качестве значения я ему указал желаемый формат aac. Кроме этого, с помощью ключа -b:a я указал желаемый битрейт получаемого файла, 160k означает 160 kbps. В конце команды я указал имя получаемого файла с расширением .m4a.
Вбиваю команду в приглашение командной строки терминала и жму enter. Внимание на следующий снимок экрана.
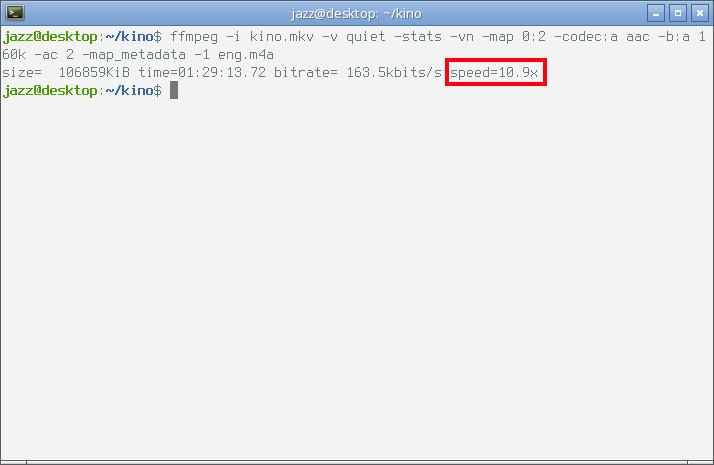
Как видно, скорость кодирования встроенным в ffmpeg энкодером оказалась самой низкой из всех продемонстрированных выше примеров. И в данном случае мне интересно детально рассмотреть параметры полученного в результате такого кодирования файла. Сделать это можно с помощью команды faad, если одноимённый пакет установлен в системе. Ещё раз обратим внимание на следующий снимок экрана с выхлопом этой команды.
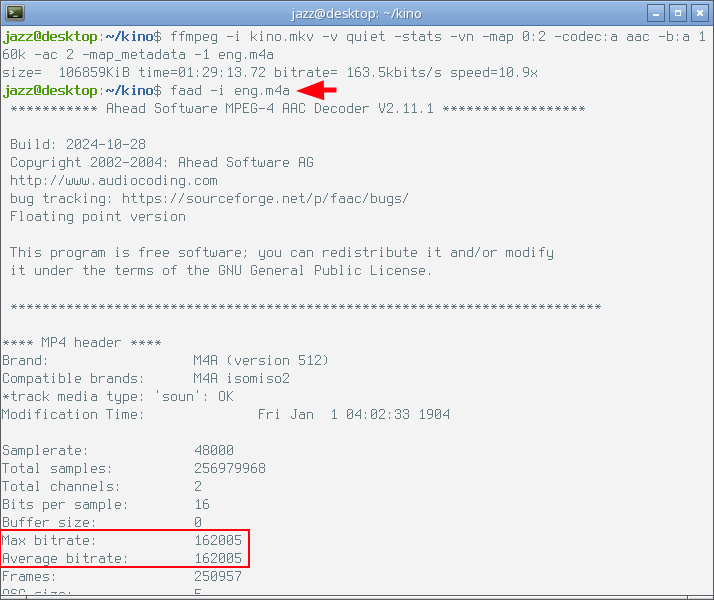
Красным фломастером я выделил битрейт полученного файла, программа показала значения среднего и максимального битрейтов, и в данном случае они идентичны, то есть встроенный в ffmpeg энкодер кодирует aac с постоянным битрейтом. Не good...
Теперь давайте воспользуемся внешним, сторонним энкодером — faac, увы, нативного яблочного энкодера в Debian не подвезли, проприетарное...
Чтобы воспользоваться faac мне нужно получить PCM Wav поток с помощью команды ffmpeg и отдать его stdout на вход программе faac. Вот как выглядит команда.
$ ffmpeg -i kino.mkv -v quiet -stats -vn -map 0:2 -codec:a pcm_s16le -ac 2 -map_metadata -1 -f s16le - | faac -v0 -b 160 -R 48000 -X -o eng1.m4a -
Здесь следует обратить внимание, как я указал формат выхлопа в команде ffmpeg, ключ -f s16le определяет, что в программный канал будет отдан сырой PCM поток заданного формата. При этом в команде faac, которая принимает отданный ffmpeg поток я указал битрейт с помощью ключа -b 160, а ключом -R 48000 — частоту дискретизации входящего потока. Частота дискретизации известна из параметров исходного аудио, их мы видели выше в выхлопе ffprobe. Внимание на следующий снимок экрана.
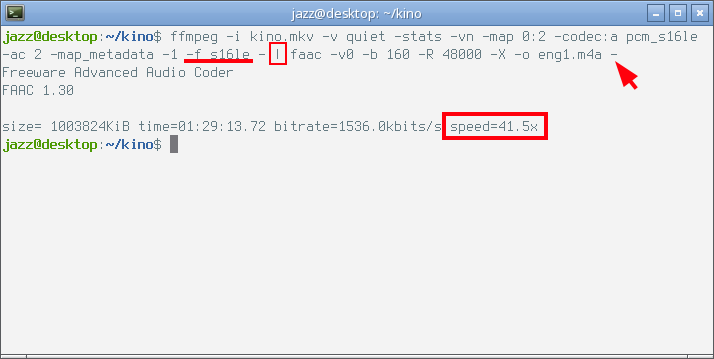
На снимке экрана выше видно, что скорость кодирования внешним энкодером в без малого четыре раза выше, чем в предыдущем примере. А если посмотреть на параметры полученного файла...
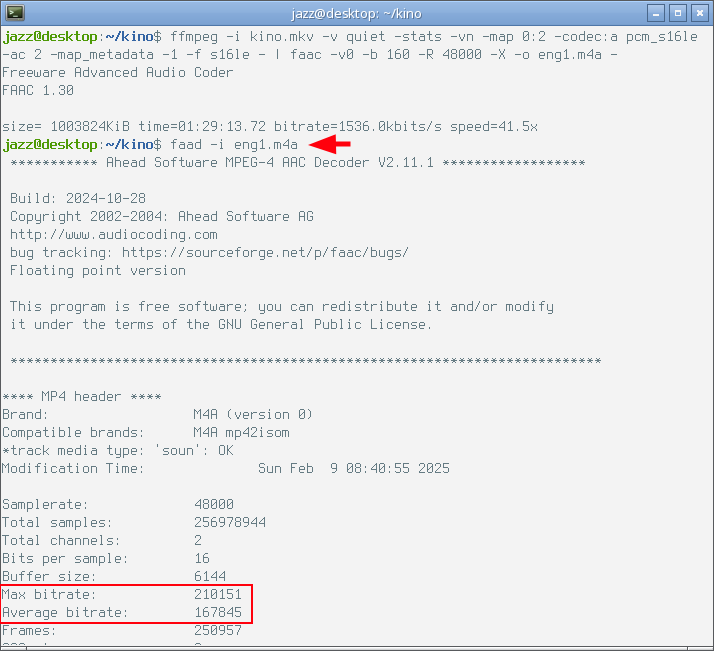
То можно увидеть, что файл имеет переменный битрейт. На мой взгляд, выбор внешнего энкодера выглядит более обоснованным.
Выводы
В результате предпринятых в этой демонстрации усилий, в моей текущей рабочей директории появился набор файлов. Давайте посмотрим на их размер в МиБ с помощью команды du.
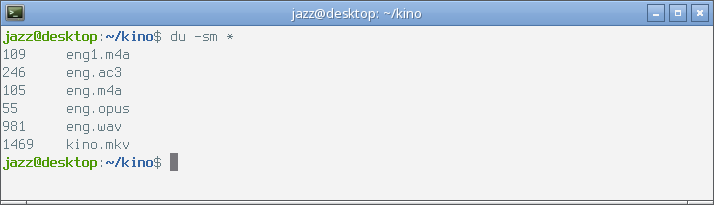
Размер файла формата Opus за счёт низкого битрейта выглядит на фоне других конкурсантов очень выгодно. Оба файла формата AAC имеют вдвое больший размер, но отличить их в слепом прослушивании от файла Opus вряд ли удастся обычному человеку.
Файл формата Wav по сравнению с остальными участниками эксперимента имеет запредельный размер, этот формат вряд ли стоит использовать для хранения, а избежать его записи на диск можно достаточно просто использованием программного канала.
Заключительный вывод я делать конечно же не буду, каждый решает сам, как кодировать своё аудио, я лишь продемонстрировал вероятные варианты и рабочие строчки для командной строки. А цель этой демонстрации полностью достигнута. Занавес..!